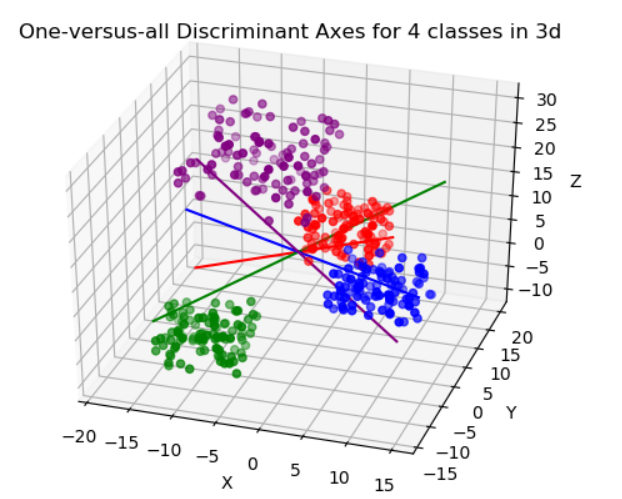
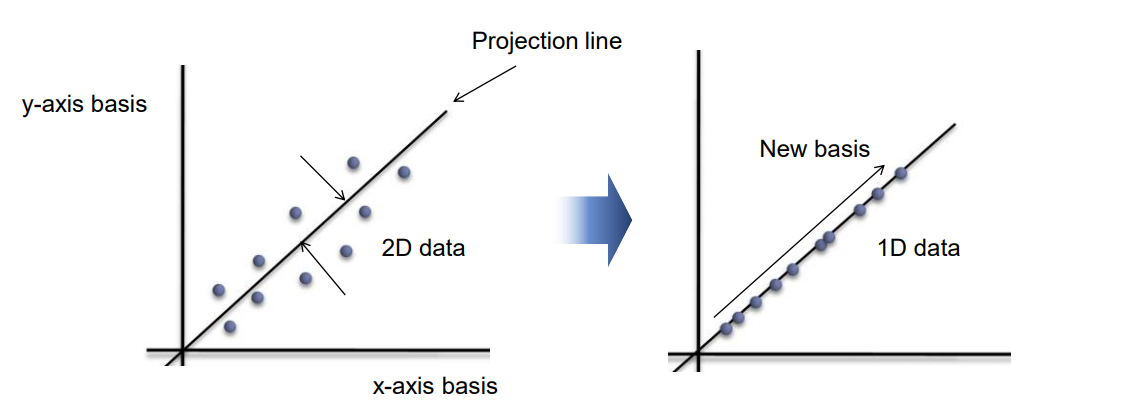
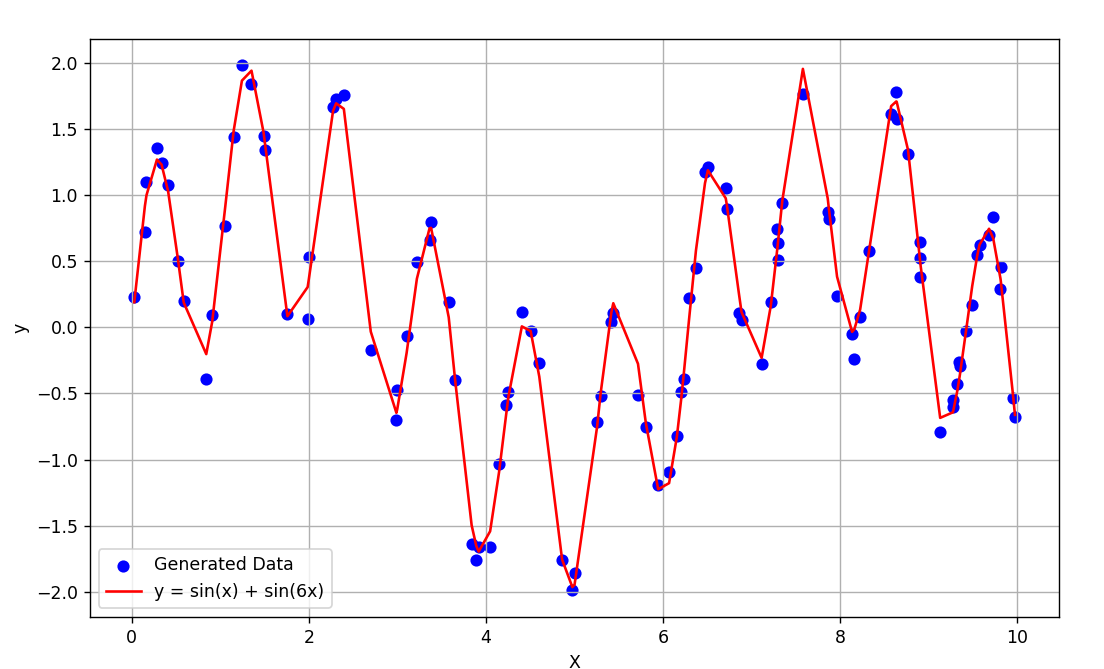
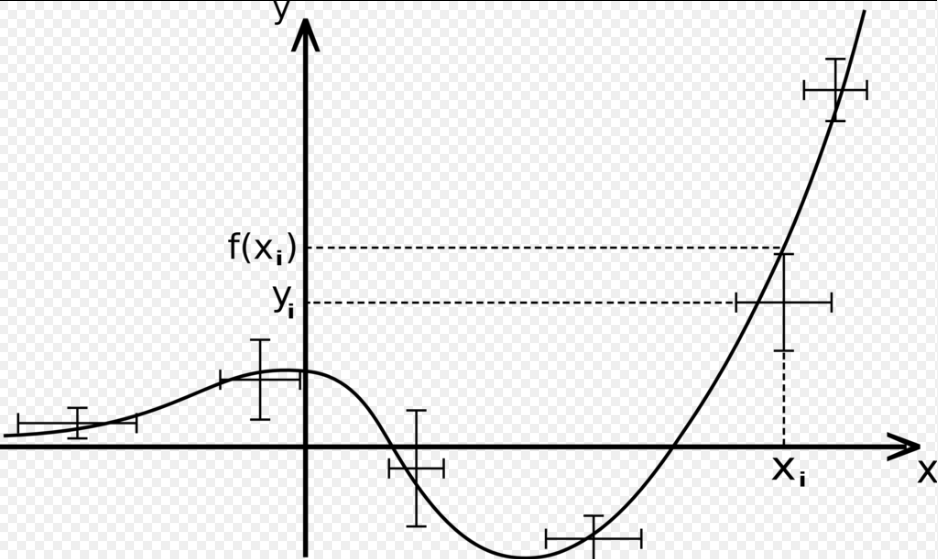
Linear Discriminant Analysis 개요 선형 판별 분석(Linear Discriminant Analysis, LDA)은 데이터를 차원 축소하고 분류하는 지도 학습 기법 중 하나다. LDA는 PCA와 유사한 점을 가지고 있지만, 클래스 레이블 정보를 활용하며, 분류 목적에 최적화된 축을 찾는 데 중점을 둔다. 이번 시간에선 LDA의 원리와 적용 방법에 대해 다루어보겠다. 본문 Supervised Learning 지도 학습(Supervised Learning) 은 입력 데이터와 그에 상응하는 정답 레이블을 사용하여 모델을 학습시키는 방식을 의미한다. 이러한 방식은 모델이 입력 데이터와 출력 레이블 간의 패턴을 학습하게 해, 미래의 유사한 데이터에 대한 출력을 예측하도록 한다. LDA는 주어..