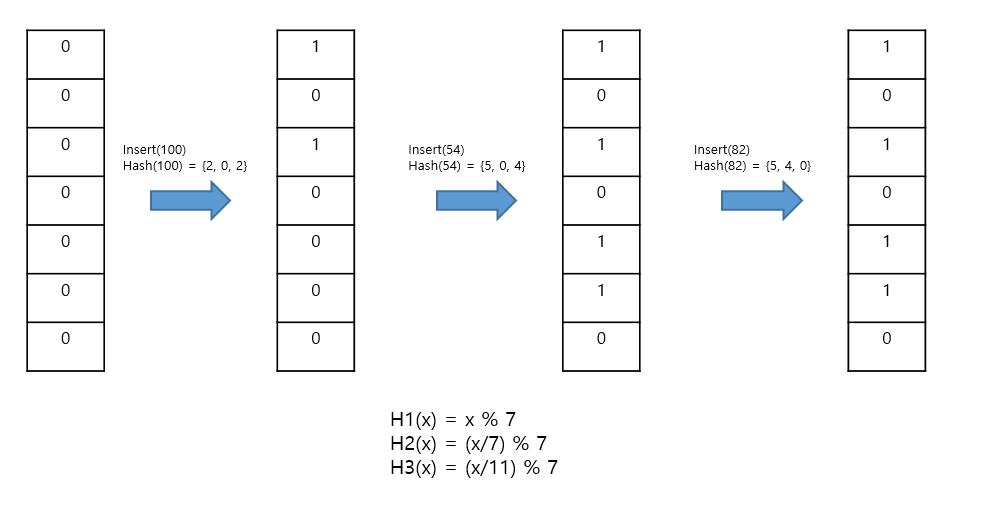
블룸 필터개요 블룸 필터(Bloom filter)는 크기가 m인 비트 배열과 k개의 독립적인 해시 함수로 구성된 확률적 데이터 구조다. 컨테이너다. 초기에 모든 비트가 0으로 설정되어 있으며, 원소를 추가할 때마다 각 해시 함수를 사용하여 계산된 인덱스에 해당하는 비트를 1로 설정하는 방식으로 작동한다. 해시 테이블과 비슷하지만, 공간 효율이 매우 높다. 특징 블룸 필터의 가장 큰 특징은 공간 효율성이다. 원소를 직접 저장하지 않고 비트 배열을 사용해 원소의 존재 여부를 추적함으로써 메모리를 효율적으로 사용한다. 그러나, 비트를 이용한 데이터를 처리하는 방식으로 인해 거짓 - 양성이라는 부정확한 결과를 얻을 수 있다. 여기서 거짓 - 양성(false positive)이란 원소가 실제로 필터에 없지만 존재..