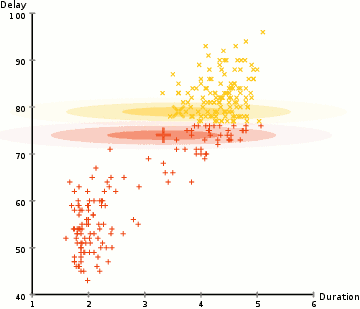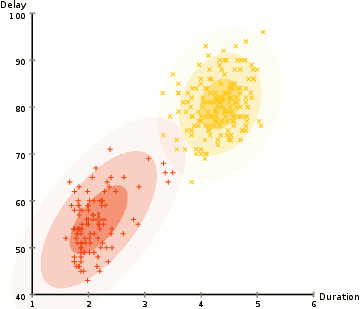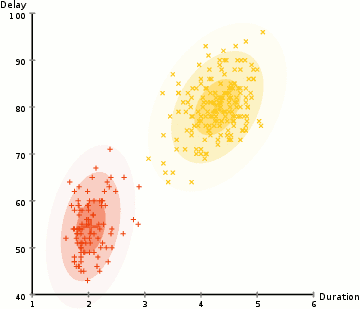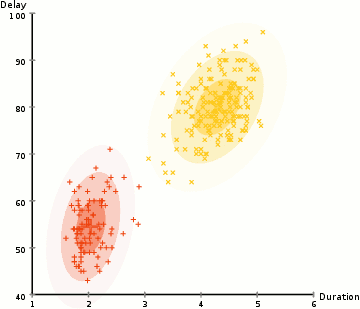
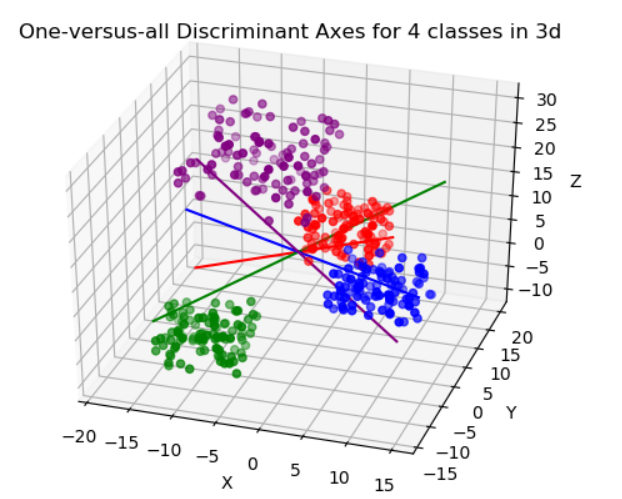
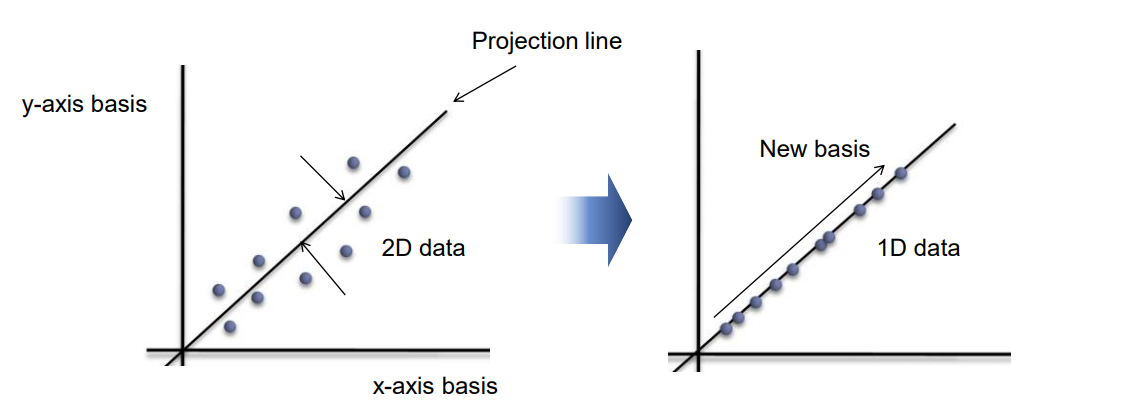
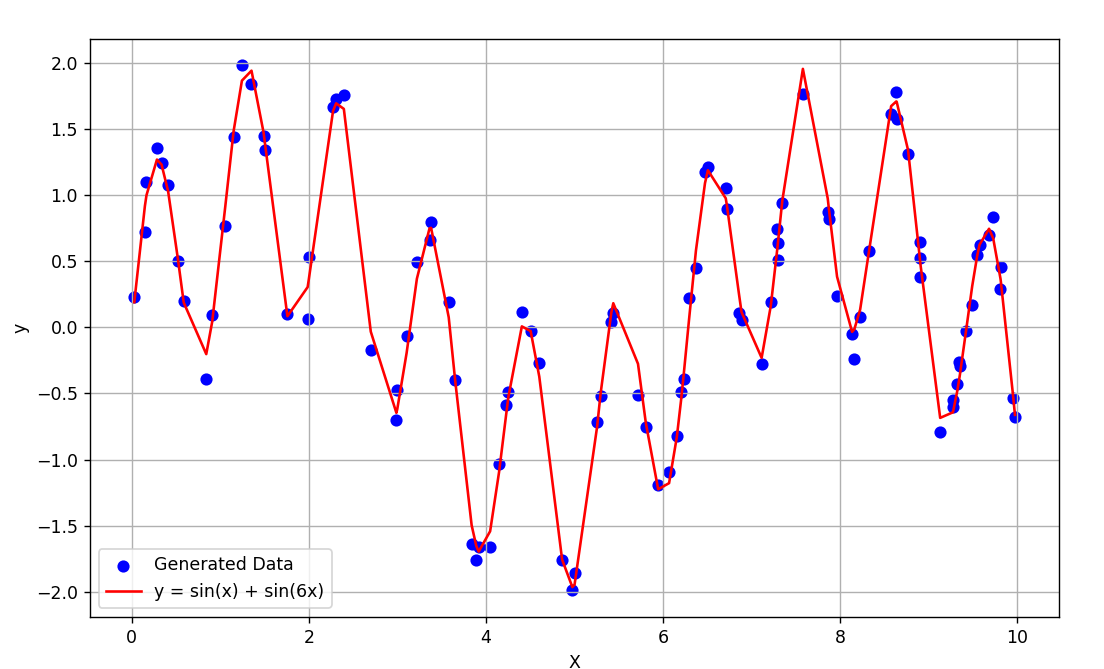
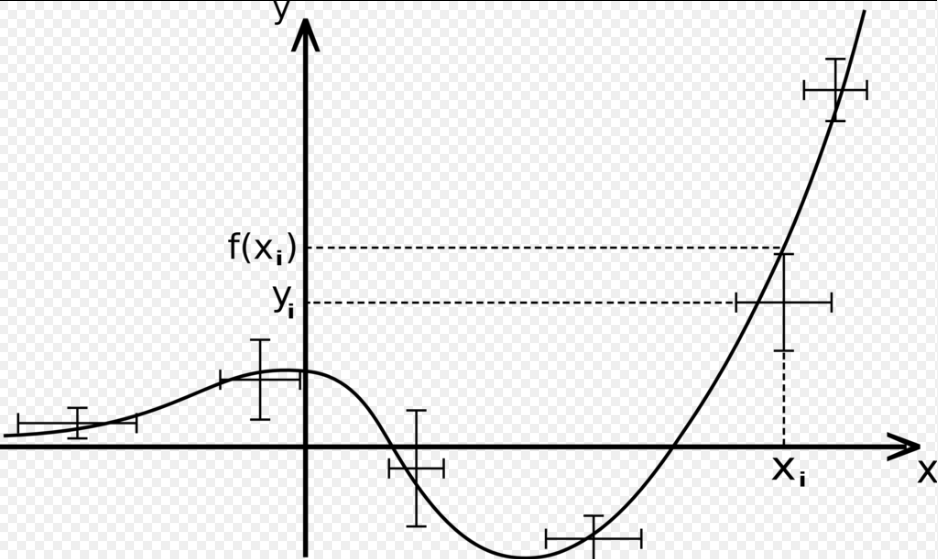
Data Clustering 개요 데이터 클러스터링(Data Clustering)은 비슷한 특성을 가진 데이터들을 같은 그룹으로 묶는 과정을 의미한다. 이를 통해 데이터를 분류하거나 단순화할 수 있으며, 레이블이 없는 데이터를 처리하므로 비지도 학습으로 분류된다. 클러스터링은 데이터의 이해를 돕고, 숨겨진 패턴을 발견하는 데 유용하게 사용된다. 데이터 클러스터링은 크게 Hard Clustering과 Soft Clustering으로 나뉜다. Hard Clustering은 각 데이터 포인트를 하나의 클러스터에 할당하는 방식이고, 대표적인 알고리즘으로 K-means Algorithm이 있다. 반면, Soft Clustering은 데이터 포인트를 여러 클러스터에 확률적으로 할당하는 방식으로, Expectatio..