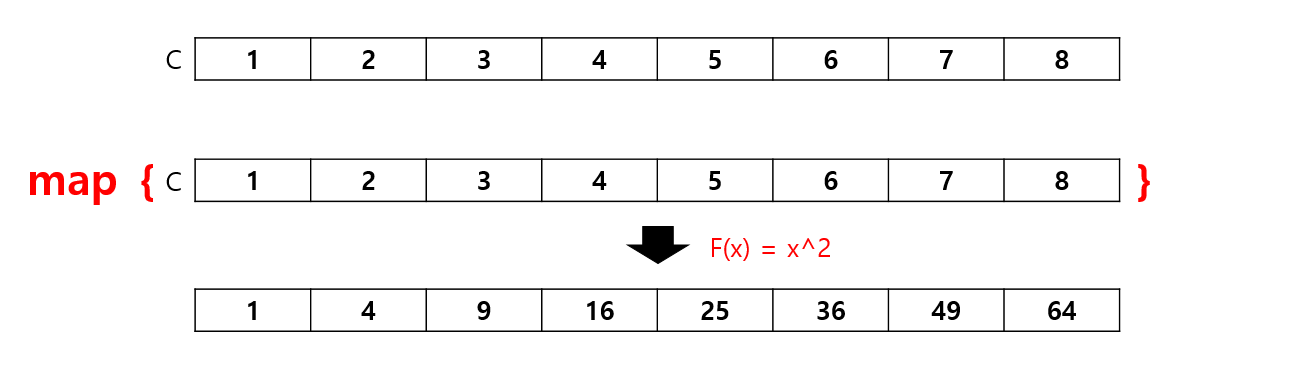
맵리듀스개요 지금까지 우리가 다룬 분할 정복은 주로 알고리즘 설계 패러다임으로 간주했다. 이번엔 이 방식을 일반 컴퓨팅 환경을 초월한 고성능 컴퓨터에 적용하는 방법에 대해 논의하려고 한다. 이러한 확장의 핵심에는 컴퓨터 클러스터(Cluster)라는 개념이 있다. 컴퓨팅 클러스터, 즉 복수의 컴퓨터를 네트워크로 연결하여 단일 시스템처럼 작동하게 하는 방식으로, 이를 통해 더 복잡하고 규모가 큰 문제를 효과적으로 해결할 수 있다. 하지만, 단순히 컴퓨팅 리소스를 확장하는 것만으로 대규모 데이터 처리에 필요한 세밀함과 효율성을 보장하긴 어렵다. 이러한 관점에서 맵리듀스(MapReduce)는 대용량 데이터를 효과적으로 처리할 수 있는 프로그래밍 모델이다. 맵리듀스는 컴퓨팅 클러스터를 활용해 거대한 양의 데이터..