<본 카테고리는 "코딩 테스트를 위한 자료 구조와 알고리즘 with C++을 기반으로 작성하였습니다>
맵리듀스
개요
지금까지 우리가 다룬 분할 정복은 주로 알고리즘 설계 패러다임으로 간주했다. 이번엔 이 방식을 일반 컴퓨팅 환경을 초월한 고성능 컴퓨터에 적용하는 방법에 대해 논의하려고 한다. 이러한 확장의 핵심에는 컴퓨터 클러스터(Cluster)라는 개념이 있다. 컴퓨팅 클러스터, 즉 복수의 컴퓨터를 네트워크로 연결하여 단일 시스템처럼 작동하게 하는 방식으로, 이를 통해 더 복잡하고 규모가 큰 문제를 효과적으로 해결할 수 있다.
하지만, 단순히 컴퓨팅 리소스를 확장하는 것만으로 대규모 데이터 처리에 필요한 세밀함과 효율성을 보장하긴 어렵다. 이러한 관점에서 맵리듀스(MapReduce)는 대용량 데이터를 효과적으로 처리할 수 있는 프로그래밍 모델이다. 맵리듀스는 컴퓨팅 클러스터를 활용해 거대한 양의 데이터를 신속하고 안정적으로 처리하는 역할을 수행한다.
특징
맵리듀스의 프로세스는 크게 두 단계, 즉 Map 단계와 Reduce 단계로 나뉜다.
- Map 단계: 입력 데이터를 분할하여 병렬 처리하는 단계. 각 부분은 독립적으로 처리되고, 결과는 key-value 쌍으로 출력
- Reduce 단계: Map 단계에서 출력된 key-value 쌍을 키를 기준으로 그룹화한 후, 각 그룹에 대해 값을 병합하는 단계.
여기서 맵리듀스가 대규모 데이터 처리에 효과적인 이유가 드러난다. 데이터를 여러 개의 작은 문제로 분할(Map)하여 여러 노드에서 동시에 처리하고, 그 결과를 병합(Reduce) 하여 전체 결과를 도출하는 병렬 처리 방식을 채택하기 때문이다. 즉, 컴퓨팅 리소스를 최대한 활용한다는 의미다.
또한 컴퓨팅 클러스터의 크기가 증가함에 따라 성능이 선형적으로 증가하는 성질이 있다. 따라서 데이터 크기가 커져도, 더 많은 노드들을 추가함으로써 처리 속도를 유지할 수 있다. 즉, 맵리듀스가 확장성이 뛰어난 프레임워크라는 점이다.
분할 정복 기법과의 연관성
하지만 우리가 주목할 것은 프로그래밍 패러다임의 일환으로 맵리듀스를 다루는 것이므로, 맵리듀스와 분할 정복 기법 간의 연관성에 대해 주목할 것이다. 먼저 Map과 Reduce의 연산 개념에 대해 간단하게 알아보자.
먼저 맵 연산은 컨테이너를 입력으로 받아, 컨테이너의 모든 원소에 함수 f(x)를 적용하는 연산이다. 예를 들어 C = {1, 2, 3, 4, 5, 6, 7, 8}이고 f(x) = x^2이라고 가정하면 다음과 같이 컨테이너의 원소가 바뀐다.
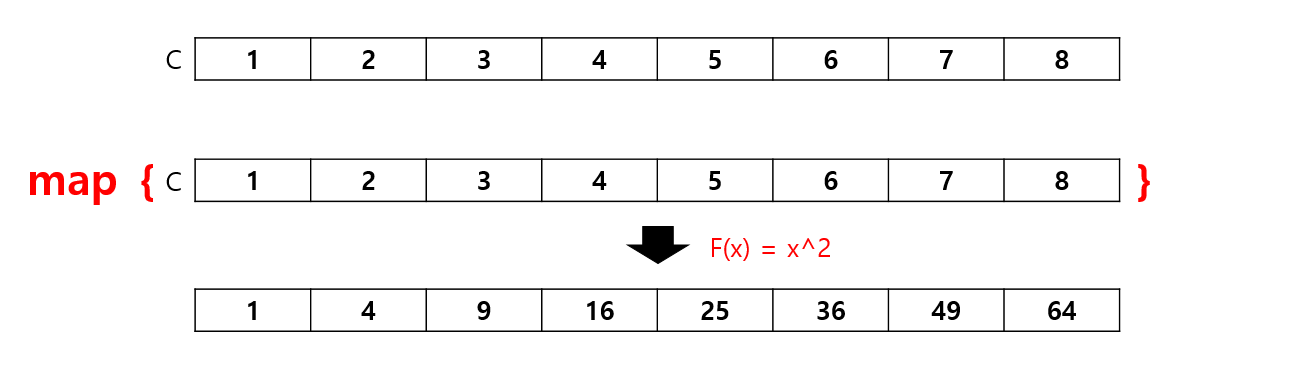
리듀스 연산은 컨테이너의 모든 원소에 함수를 적용하여 하나의 값으로 축약하는 연산이다. 예를 들어 C = {1, 2, 3, 4, 5, 6, 7, 8} 이고 f(a,x) = a+x라고 가정하면 다음과 같이 값이 병합된다.

즉, 하나의 데이터 셋을 처리할 때 map 단계와 reduce 단계로 분할한다는 점에서 분할 정복 기법의 개념이 사용되는 것이다. C++ 표준 라이브러리는 이러한 맵과 리듀스 연산을 각각 std::transform()과 std::accumulate() 함수로 제공하고 있으며, C++17부터는 병렬 처리를 지원하는 std::reduce() 함수도 제공하고 있다.
예제
일반적으로 코딩 테스트나 알고리즘 문제에서 대규모 데이터를 처리하는 경우가 드물다. 그럼에도 불구하고, 맵리듀스를 다루는 이유는 기본 원리인 맵과 리듀스를 여러 코딩 문제에서 적용할 수 있기 때문이다. 즉, 주어진 데이터에 함수를 적용해야 할 땐 맵 개념을 사용하고, 주어진 데이터를 축약할 땐 리듀스 개념을 사용하면 된다.
따라서 우리는 이러한 개념을 이해할 수 있는 예제 코드를 작성해 보자. 목표는 배열이 {1,2,3,4,5,6,7,8}의 원소를 가질 때, f(x) = x^2의 맵 연산과 f(a,x) = a + x의 리듀스 연산을 수행하는 것이다.
#include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
#include <cmath>
void print(std::vector<int>& v, std::string op)
{
std::cout << op << " operation result: ";
for (const auto& val : v)
std::cout << val << ' ';
std::cout << "\n";
}
void map_operation(std::vector<int>& v)
{
std::for_each(v.begin(), v.end(),
[](int& x) { x = std::pow(x, 2.0); });
print(v, "map");
}
void reduce_operation(std::vector<int>& v)
{
auto ans = std::accumulate(v.begin(), v.end(), 0,
[](int a, int x) {return a + x; });
std::vector<int> res { ans };
print(res, "reduce");
}
int main()
{
std::vector<int> v = { 1,2,3,4,5,6,7,8 };
print(v, "Input");
map_operation(v);
reduce_operation(v);
}

요약
맵리듀스
1. 정의: 대용량 데이터를 처리하는 프로그래밍 모델 및 구현
2. 특징: 맵 단계와 리듀스 단계로 나뉨
a. 맵(Map): 입력 데이터를 분할하여 병렬 처리하는 단계로서, key-value 쌍을 생성
-> 주어진 데이터에 함수를 적용
b. 리듀스(Reduce): Map 단계에서 출력된 key-value 쌍을 병합
-> 주어진 데이터를 축약
3. 장점
a. 확장성: 클러스터 내의 여러 컴퓨터에서 동시에 처리 가능
b. 복구 기능: 실패한 작업을 다른 노드에서 자동으로 다시 시작
c. 데이터 위치 최적화: 노드에서 데이터를 처리하여 네트워크 병목 현상 줄임
4. 단점
a. 복잡성: 모델이 복잡함
b. 실시간 처리 불가: 배치 처리를 하므로 실시간 처리가 불가능
c. 반복적인 작업, 복잡한 데이터 분석에 제한적
'CS > 알고리즘' 카테고리의 다른 글
| [알고리즘] 그리디 알고리즘 - 배낭 문제 (0) | 2023.05.23 |
|---|---|
| [알고리즘] 그리디 알고리즘 - 개요 및 최단 작업 우선 스케줄링 (0) | 2023.05.22 |
| [알고리즘] 분할 정복 - 선형 시간 선택 (2) | 2023.05.19 |
| [알고리즘] 분할 정복 - 퀵 정렬 (0) | 2023.05.16 |
| [알고리즘] 분할 정복 - 병합 정렬 (2) | 2023.05.11 |