Endianness
개요

엔디안(Endianness)은 컴퓨터 시스템에서 데이터를 메모리나 전송 매체에 저장할 때, 그 배열 순서를 결정하는 개념이다. 즉, 엔디안은 숫자나 다중 바이트 데이터(예: 16비트, 32비트, 64비트 등)를 저장하거나 전송할 때, 어떤 순서로 배열할 것인지를 나타낸다. 이 순서는 시스템의 하드웨어 구조에 따라 달라지며, 특히 메모리, 파일 포맷, 네트워크 통신 등에서 중요한 역할을 한다. 엔디안은 크게 빅 엔디안(Big-endian)과 리틀 엔디안(Little-endian)으로 나뉜다.
엔디안이 중요한 이유는 시스템 간 데이터 전송 시 엔디안의 차이는 호환성 문제를 일으킬 수 있기 때문이다. 따라서 데이터 전송 표준(예: 네트워크에서는 주로 빅 엔디안을 사용)이나 프로토콜에 따라 엔디안 변환이 필요하다. 현대의 프로세서나 소프트웨어 환경에서는 대부분 이러한 차이를 자동으로 처리하지만, 임베디드 시스템이나 저수준 프로그래밍에서는 여전히 중요한 고려 사항이다. 이번 시간에는 엔디안의 종류 중 하나인 리틀 엔디안을 살펴보고, 16진수 배열에서 각 엔디안 방식을 적용하여 값을 처리하는 방법을 알아보도록 하겠다.
본문
Little-endian
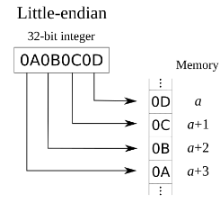
리틀 엔디안 방식은 작은 값을 먼저 저장하는 방식이다. 예를 들어, 1234라는 숫자에서 4가 가장 덜 중요한 숫자(LSB)가 되는 방식이다. 리틀 엔디안에서는 이 작은 값이 메모리의 앞쪽에 저장되고, 큰 값(MSB)이 나중에 저장된다.
이 방식은 메모리에서 작은 단위의 데이터에 접근할 때 효율적이다. 특히, 16비트나 32비트 데이터를 처리할 때, 리틀 엔디안 방식에서는 하위 바이트부터 바로 접근할 수 있기 때문에 메모리 접근 성능이 뛰어나다. 또한, 대부분의 현대 컴퓨터 아키텍처, 특히 x86 아키텍처는 리틀 엔디안을 기본으로 사용하기 때문에 이러한 시스템에서 빠르고 변환이 필요하지 않아 효율적이다.
하지만 리틀 엔디안은 숫자를 거꾸로 저장하기 때문에 사람이 읽거나 디버깅할 때 직관적이지 않아 혼동을 줄 수 있다. 또한, 네트워크 프로토콜은 대부분 빅 엔디안을 사용하기 때문에, 리틀 엔디안 데이터를 네트워크에서 사용하려면 변환이 필요하여 추가적인 처리 과정을 거쳐야 한다.
Little Endian Parsing (1) - 16진수 배열에 특정 비트 추출하기

예를 들어, 다음과 같은 CAN Message가 Little Endian 방식으로 수신되었다고 가정해 보자. 이때 offset은 0이고 factor는 1이라고 가정한다. 여기서 5번 비트부터 12번 비트까지의 값은 얼마일까?

리틀 엔디안은 작은 값이 먼저 저장되기 때문에 메모리엔 다음과 같이 저장될 것이다. 이때 특정 비트에 값을 넣는 것을 목적으로 하고 있으므로 16진수를 2진수로 변환해 준다.

여기서 5번 비트부터 12번 비트까지 값을 추출하면 다음과 같다.

즉, 0101 1010(2) = 90이 된다.
Little Endian Parsing (2) - 16진수 배열에 특정 비트 삽입하기

이번에는 빈 문자열 배열에 5번 비트부터 12번 비트까지 90이라는 10진수 값을 넣어 보자. Little Endian Parsing(1)과 마찬가지로 offset은 0이고 factor는 1이라고 가정한다. 그리고 각 문자열에 괄호로 된 숫자는 문자열 배열의 인덱스를 의미한다.

리틀 엔디안 방식이므로 순서를 바꿔주고, 특정 비트에 값을 넣기 위해 2진수로 변환해 주자.

그리고 아래와 같이 5번 비트부터 12번 비트까지 90을 2진수로 변환한 값인 0101 1010(2)을 차례대로 넣고 16진수로 변환해 보자.

여기서 바이트 순서를 반대로 적용하면 최종적으로 메시지는 다음과 같이 0x40, 0x0B, 0x00, 0x00으로 구성된다.
코드 구현
해당 내용을 Python 코드로 작성하면 다음과 같다. 파이썬의 문법을 크게 쓰지 않고 비트 연산이 주를 이루고 있기 때문에, 로직을 잘 파악하고 있다면 C언어로 변환하는 것도 크게 어렵지 않을 것이다.
# 16진수 배열의 특정 비트에 값을 넣는 예제
def update_data(data, value, start_bit, bit_length, factor):
value = int(value / factor)
data = bytearray(data)
for i in range(bit_length):
bit_value = (value >> i) & 1
byte_index = (start_bit + i) // 8
bit_index = (start_bit + i) % 8
if bit_value:
data[byte_index] |= (1 << bit_index)
else:
data[byte_index] &= ~(1 << bit_index)
return data
message = [0x00, 0x00, 0x00, 0x00]
start_bit = 5
bit_length = 8
value = 90
updated_message = update_data(message, value, start_bit, bit_length, 1)
print([hex(x) for x in updated_message])
def get_value_from_hex(data, start_bit, bit_length, factor=1):
full_value = 0
for i in range(len(data)):
full_value |= data[i] << (i * 8)
mask = (1 << bit_length) - 1
extracted_value = (full_value >> start_bit) & mask
return extracted_value * factor
if __name__ == "__main__":
message = [0x40, 0x0B, 0x00, 0x01]
start_bit = 5
bit_length = 8
factor = 1
extracted_value = get_value_from_hex(message, start_bit, bit_length, factor)
print(f"Extracted Value: {extracted_value}")
print(f"Extracted Value (binary): {bin(extracted_value)}")
'CS > 임베디드' 카테고리의 다른 글
| [임베디드] 신호와 주파수 (7) | 2024.10.08 |
|---|---|
| [임베디드] 엔디안 방식의 이해(2) with CAN Message (0) | 2024.09.30 |