<본 카테고리는 "코딩 테스트를 위한 자료 구조와 알고리즘 with C++을 기반으로 작성하였습니다>
연결된 자료 구조
앞선 시간에서 선형 자료 구조 중 연속된 자료 구조를 알아보았다. 이번 시간에는 여러 개의 메모리 청크인 노드(Node)에 데이터를 저장하는 연결된(Linked) 자료 구조를 연결된 자료 구조의 대표격인 연결 리스트를 통해 알아보자.
노드(Node): 연결 지점
연결 리스트(Linked list)란 각각의 노드가 저장할 데이터와 다음 노드를 가리키는 포인터를 갖고 있는 자료 구조를 의미한다. 이때 노드가 한 쪽 방향으로만 탐색이 가능한 것을 단일(Singly) 연결 리스트라고 하고, 앞 뒤 방향 모두 탐색이 가능한 것을 양방향(Doubly) 연결 리스트라고 한다. 이러한 연결 리스트를 그림으로 표현하면 다음과 같다.
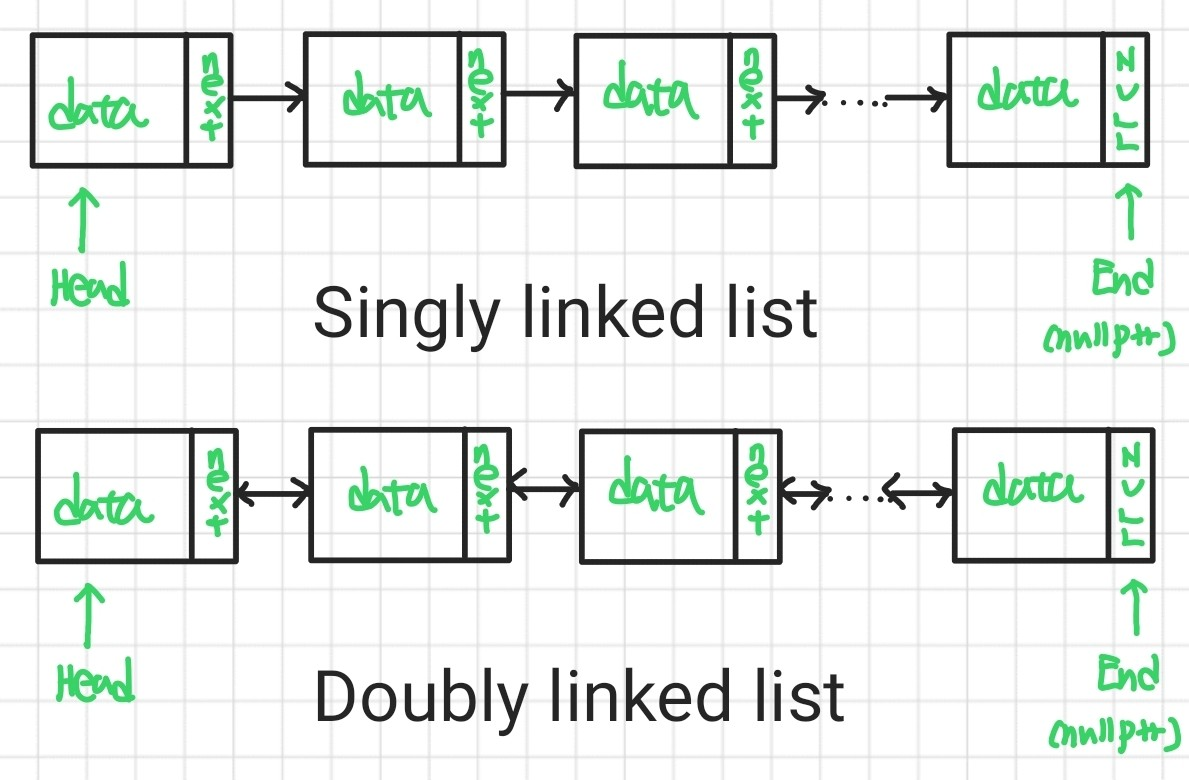
이러한 개념에 착안하여 한 번 코드로 연결 리스트를 구현해보겠다.
template <class T>
class Node
{
public:
Node* _next = nullptr;
Node* _prev = nullptr;
T _data;
public:
Node()
{
}
Node(const T& value) : _next(nullptr), _prev(nullptr), _data(value)
{
}
};먼저 리스트 클래스를 구현하기 전에 노드라는 정보가 필요하므로 노드 클래스 Node를 만들어 줘야 한다. Node를 불러올 때 이전 정보와 다음 정보, 그리고 데이터가 필요하므로 세 개의 멤버 변수를 만들어 주고 이에 맞는 생성자도 초기화해준다.
template <class T>
class List
{
Node<T>* _header;
int _size = 0;
public:
List()
{
_header = new Node<T>();
_header->_next = _header;
_header->_prev = _header;
}이제 본격적으로 리스트를 구현해보자. 먼저 처음에 리스트가 생성될 때 size가 0일 것이다. 이때 노드의 다음 주소 _next와 이전 주소 _prev가 가리키는 것이 없어야 하므로 모두 자기 자신을 가리키도록 설정해준다.
// [1] [2] [prev] [node] [before]
Node<T>* AddNode(Node<T>* before, const T& value) // 이전 주소랑 값을 갖는 노드 추가
{
Node<T>* node = new Node<T>(value); // 새로운 [node] 생성
Node<T>* prevNode = before->_prev; // 이전 노드의 값을 갖는 [prev] 노드
prevNode->_next = node; // [prev] -> [node]
node->_prev = prevNode; // [prev] <- [node]
node->_next = before; // [node] -> [before]
before->_prev = node; // [node] <- [before]
_size++;
return node;
}이제 노드가 추가되었을 때를 생각해보자. 우리는 마지막 노드 before와, before가 가리키는 이전 노드 _prev 사이에 새로운 노드를 추가할 것이다. 노드가 추가될 때는 이전 노드의 정보 before와 데이터 value를 가져올 것이다. 먼저 데이터 value를 갖는 새로운 노드 node를 선언하고, 이전 노드 prevNode를 이전 노드의 값을 갖게 초기화 해준다. 여기서 prevNode가 이전 노드의 값을 갖게 해준다는 것이 잘 와닿지 않을 것이다. 예를 들어 리스트에 다음과 같이 데이터가 4개가 있다고 가정해보자.

여기서 새로운 노드가 추가되면 어떻게 될까? 그리고 여기서 before 노드는 무엇이고, _prev 노드는 무엇일까? 이를 새로 들어오는 노드 node의 입장에서 보면 기존의 상태는 이렇게 되어 있었을 것이다.
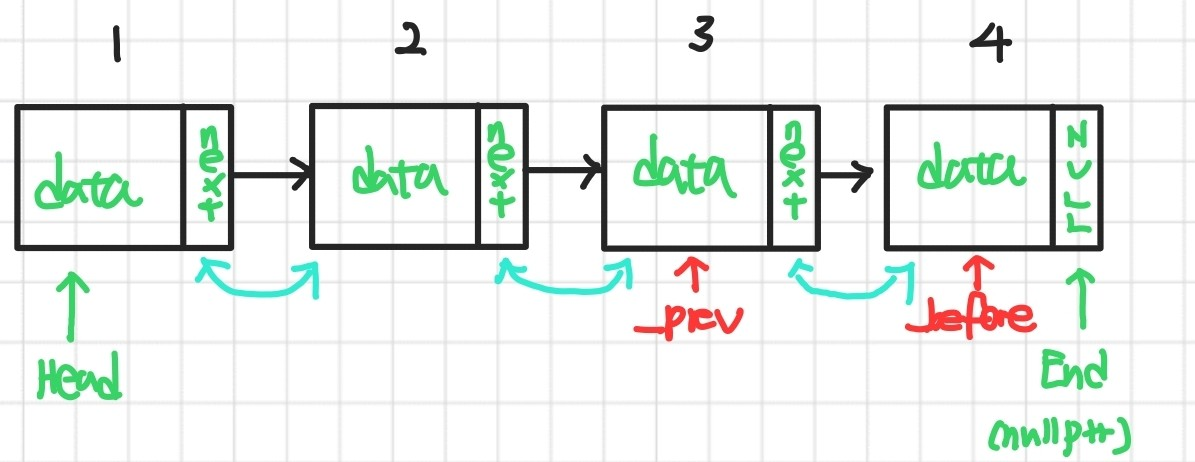
따라서 새로운 노드가 3번과 4번 사이에 들어오면 이렇게 될 것이다.

이제 노드를 삭제하는 코드를 만들어보자.
// [1] [2] [prev] <-> [node] <-> [next]
Node<T>* RemoveNode(Node<T>* node)
{
Node<T>* prevNode = node->_prev;
Node<T>* nextNode = node->_next;
prevNode->_next = nextNode; // [prev] -> [next]
nextNode->_prev = prevNode; // [prev] <- [next]
delete node; // [node] 삭제
_size--;
return nextNode;
}node를 삭제한다고 하면, [node]를 끊기 전에, [prev]와 [next]를 서로 연결해주면 될 것이다.
이를 모두 종합하여 작성하면 다음과 같다.
template <class T>
class Node
{
public:
Node* _next = nullptr;
Node* _prev = nullptr;
T _data;
public:
Node()
{
}
Node(const T& value) : _next(nullptr), _prev(nullptr), _data(value)
{
}
};
template <class T>
class List
{
public:
Node<T>* _header;
int _size = 0;
public:
List()
{
_header = new Node<T>();
_header->_next = _header;
_header->_prev = _header;
}
Node<T>* AddNode(Node<T>* before, const T& value)
{
Node<T>* node = new Node<T>(value);
Node<T>* prevNode = before->_prev;
prevNode->_next = node;
node->_prev = prevNode;
node->_next = before;
before->_prev = node;
_size++;
return node;
}
Node<T>* RemoveNode(Node<T>* node)
{
Node<T>* prevNode = node->_prev;
Node<T>* nextNode = node->_next;
prevNode->_next = nextNode;
nextNode->_prev = prevNode;
delete node;
_size--;
return nextNode;
}
};만약 우리가 사용하는 list처럼 push_back(), pop_back(), iteartor 등을 구현한 코드를 보고 싶으면 여기를 눌러 linked_list코드를 보면 된다. 아마 노드를 연결하고 지우는 개념이 어렵지, 나머지 기능을 구현하는 것은 크게 어렵지 않을 것이다.
이러한 연결리스트의 특징은 모두 이어져 있어서 i번째 원소에 접근하려면 연결 리스트 내부를 i번 이동해야 하므로 O(n)의 시간 복잡도를 가진다는 것이다. 이는 곧 원소가 메모리에 연속적으로 저장되지 않기 때문에 배열과 달리 캐시 지역성을 기대할 수 없다는 의미다. 하지만 포인터를 이용하여 원소의 삽입/삭제를 매우 빠르게 수행할 수 있다.
요약
연결된 자료 구조
1. 정의: 노드로 이어진 자료 구조
2. 특징
a. 각각의 노드는 저장할 데이터와 다음 노드를 가리키는 포인터를 갖고 있음
b. 캐시 지역성이 없음
배열과 리스트의 비교
지금까지 연속된 자료 구조와 연결된 자료 구조를 알아보았다. 이 둘의 차이점을 한 눈에 알아보기 위해 표로 정리해보았다.
| 배열 | 리스트 | |
| 데이터 저장 구조 | 메모리에 연속적으로 저장 | 노드에 데이터 저장 |
| 임의 원소 접근 | 빠름 ( O(1) ) | 느림 ( O(n) ) |
| 캐시 지역성 | O (데이터 순회 속도 빠름) | X (데이터 순회 속도 느림) |
| 메모리 사용량 | 정확하게 데이터 크기만큼 사용 | 다음 포인터를 가리키기 위한 여분의 메모리 사용 |
| 맨 뒤 원소 삽입 속도 | 빠름 ( O(1) ) | 빠름 ( O(1) ) |
| 중간 원소 삽입 속도 | 느림 ( O(n) ) | 빠름 ( O(1) ) |
이러한 C 스타일의 배열은 몇 가지 제약사항이 존재하여 그닥 많이 사용되지는 않는다.
- 메모리 할당과 해제를 수동으로 처리해야 함
- [] 연산자에서 배열 크기보다 큰 원소를 참조하는 것을 검사하지 못함
- 깊은 복사가 기본으로 동작하지 않음
이러한 제약사항을 극복한 것이 std::array인데, 이는 다음 시간에 알아보도록 하자.
'CS > 자료구조' 카테고리의 다른 글
| [자료구조] std::forward_list (0) | 2023.02.20 |
|---|---|
| [자료구조] vector with C++ (2) (0) | 2023.02.11 |
| [자료구조] vector with C++ (1) (0) | 2023.02.10 |
| [자료구조] std::array with C++ (0) | 2023.02.02 |
| [자료구조] 연속된 자료 구조와 연결된 자료구조 (1) with C++ (2) | 2023.01.26 |