영어 단어 시험지 코드 리뷰
본문
구성
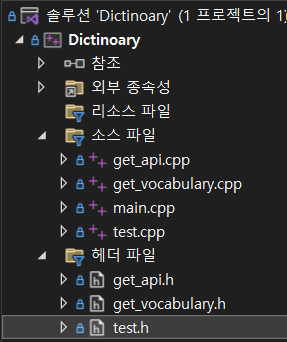
ver 1.1 기준으로 해당 프로그램은 다음과 같이 API를 호출하는 부분(get_api.h/get_api.cpp), JSON 파일을 파싱해 단어를 저장하는 부분(get_vocabulary.h/get_vocabulary.cpp), 시험을 출력하는 부분(test.h/test.cpp), 메인 함수(main.cpp)로 구성되어 있다.
즉, 프로그램을 실행하면 Notion의 API를 호출하여 데이터베이스와 연결하고, 단어들을 JSON 구조로 추출하여 DOS 창에서 단어가 나오면 정답을 입력하게 되어 있다. 자세한 코드는 해당 리포지토리를 확인하면 된다.
API 호출

저번 게시글에서도 언급했듯이, C++에서 Notion API를 호출하는 것은 번거로운 작업이다. 그래서 system() 함수를 이용하여 외부 스크립트(여기선 파이썬 스크립트)를 실행시켜 API 작업을 진행하였다. 이때 콘솔창의 인코딩은 UTF-8이 아니므로 SetConsoleCP() 함수와 SetConsoleOutputCP() 함수를 이용하여 콘솔의 인코딩을 UTF-8로 설정하였다.

API를 호출하는 파이썬 스크립트 GetNoitonAPI.py 파일이다. 먼저 데이터베이스 ID와 API Key가 존재하는지 확인하기 위해 .env 파일의 존재 여부를 확인한다. 만약 존재하지 않는다면 API Key와 DB ID를 입력으로 받고, .env 파일을 같은 디렉터리 내에 저장한다. 만약 키가 잘못되었으면 check_key_valid() 함수를 실행시켜 값을 변경시킬 수 있게 해 놓았다.
정상적으로 연결에 성공하였으면, 노션 API를 호출하여 데이터를 받아온다. 그리고 받아온 데이터를 output.txt로 저장한다.
단어 쌍 추출

API를 호출하여 JSON 구조를 저장한 output.txt를 순회하며 필요한 단어와 그 정의를 _word_pairs에 담는 게 목적인 클래스다. 따라서 파일 스트림을 이용하여 output.txt를 읽고, json 객체를 이용하여 json 문자열을 파싱하여, 파싱한 결과를 문자열 스트림을 이용해 결과 문자열에 담는 과정이 필요하다.

클래스 생성자를 통해 멤버 변수들을 초기화하였다. 이때 생성자 초기화 목록(Constructor Initialization List)을 사용하였으며, 릴리즈 모드에서 에러를 방지하기 위해 명시적으로 초기화하였다.
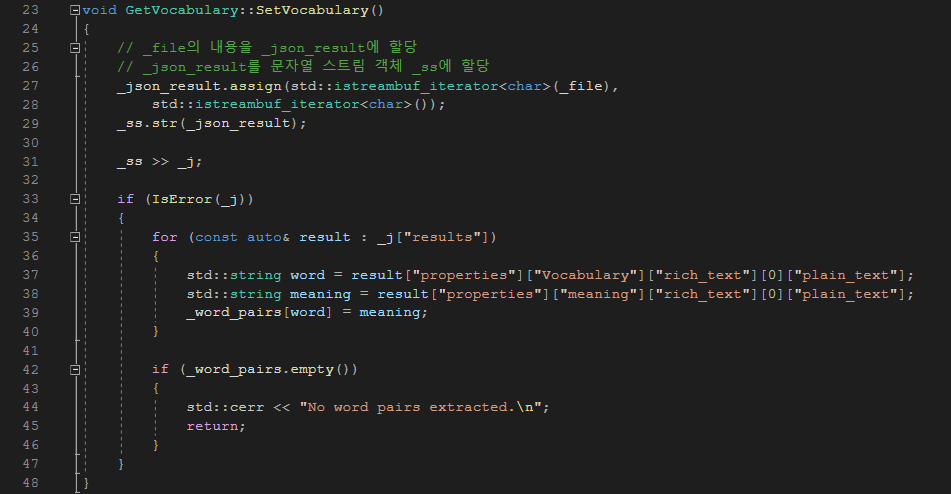
단어 맵에 단어 쌍을 저장하는 SetVocabulary() 함수다. 초기엔 생성자에서 단어를 저장하는 작업을 하게 설정했는데, 프로그램을 실행시켰을 때 동기화의 문제가 생겨 따로 함수를 설계하였다.
json 결과 문자열 _json_result의 인자는
- std::istreambuf_iterator: 스트림 버퍼에 대한 반복자(iterator). 주로 파일이나 다른 입력 스트림에서 문자들을 순차적으로 읽어 들일 때 사용
- std::istreambuf_iterator<char>(_file): _file이라는 ifstream 객체 (파일 입력 스트림)의 시작 위치를 가리키는 반복자를 생성
- std::istreambuf_iterator<char>(): 스트림의 끝(end)을 나타내는 반복자를 생성
즉, _file에서 전체 파일 내용을 _json_result 문자열에 읽어 들인 후, 그 문자열을 _ss라는 입력 스트림에 설정하는 동작을 수행한다. 이때 에러가 생기지 않았다면 결과 문자열을 순회하며 단어를 저장한다. 여기서 우리가 가져와야 할 프로퍼티는 Vocabulary와 meaning이므로, result["properties"]["Vocabulary"] 혹은 result["properties"]["meaing"]으로 시작하는 구조를 찾아야 한다. 이때 노션 JSON 데이터 내부를 보면

이런 식으로 rich_text의 plain_text에 접근해야 한다는 걸 알 수 있다. 이러한 작업이 끝나고 만약 맵이 비어있다면 단어 쌍이 없다고 출력하게 설정하였다.
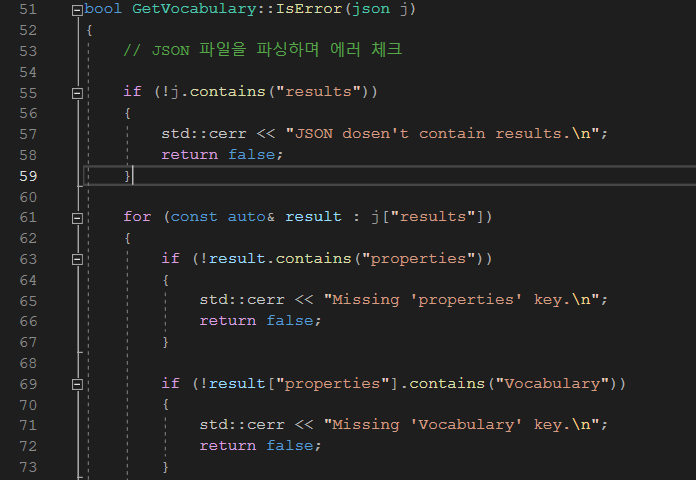
JSON 파일을 파싱할 때 에러를 추출하는 부분이다. 사실 에러 추출과 동시에 단어 쌍을 저장해도 되지만, 필자가 처음 작업할 때 파싱을 실패하는 경우가 너무 많아 다음과 같이 에러를 추출하는 함수를 따로 지정하였다.
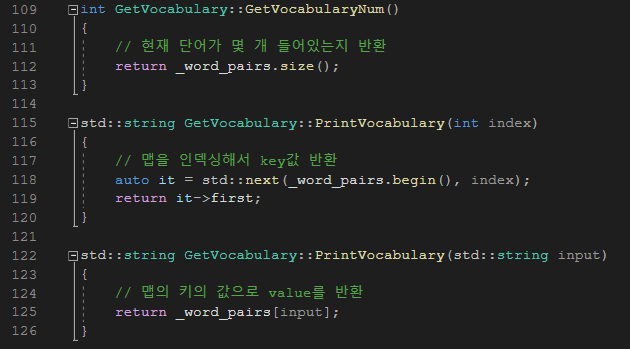
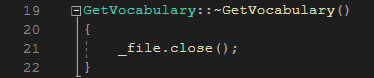
그리고 테스트지에서 호출해야 하는 메서드들을 구현하였고, 소멸자를 통해 파일 스트림을 닫아주었다.
시험지 생성
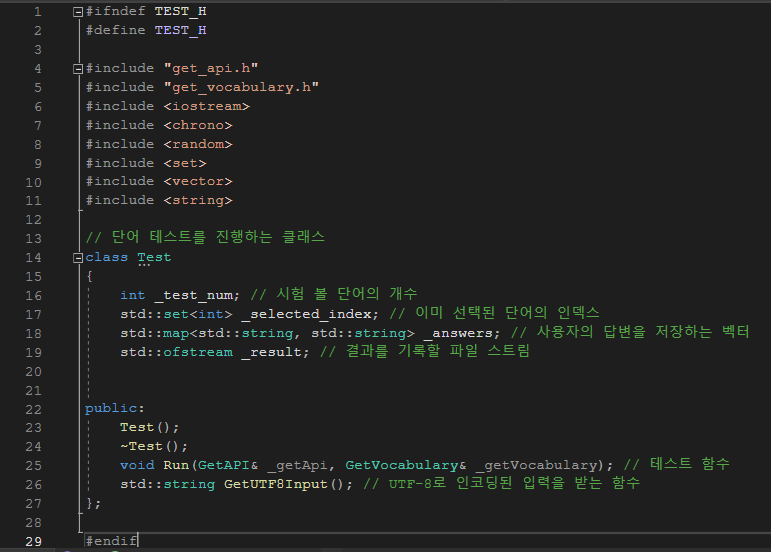
단어 테스트를 진행하는 Test클래스다. 시험 볼 단어의 개수를 입력받고, 해당하는 수만큼 단어를 랜덤으로 출력하게 구성하였다. 이때 한 번 선택된 단어는 다시 선택될 수 없게 인덱스를 set으로 지정하여 중복을 피했으며, 최종 결과를 txt 파일로 출력하기 위해 사용자의 답변을 저장하는 벡터와 파일 스트림을 멤버 변수로 추가하였다.
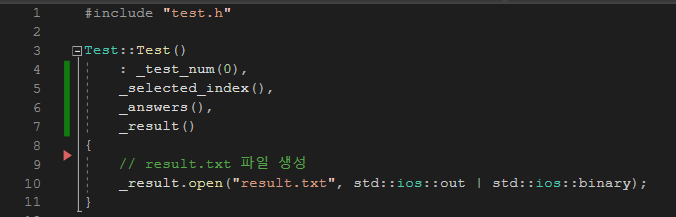
Test의 멤버 변수들 또한 생성자 초기화 리스트를 이용해 초기화해 주었으며, 결과 result.txt를 저장할 파일 스트림 _result를 쓰기용과 이진 모드로 열도록 설정하였다. 만약 파일이 이미 존재한다면, 파일의 내용은 지워지고 처음부터 새롭게 기록된다.
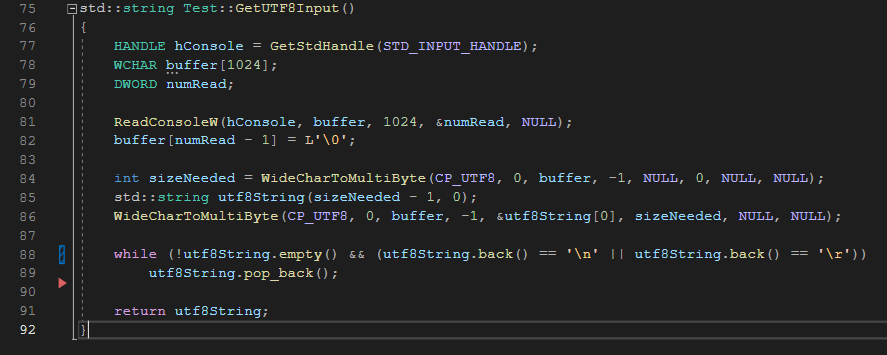
사용자의 답변 벡터에 문자열을 저장할 때 UTF-8로 형식을 지정하는 함수다. 콘솔의 표준 입력 핸들을 가져와, 사용자 입력을 저장할 UTF-16 문자열 버퍼를 선언하여, 실제로 읽은 문자 수를 저장하는 변수를 이용하였다. 솔직히 이 부분이 가장 시간이 오래 걸렸는데, 필자도 윈도 API를 이해하지 못한 상황에서 여기저기 끌어 썼다(...).
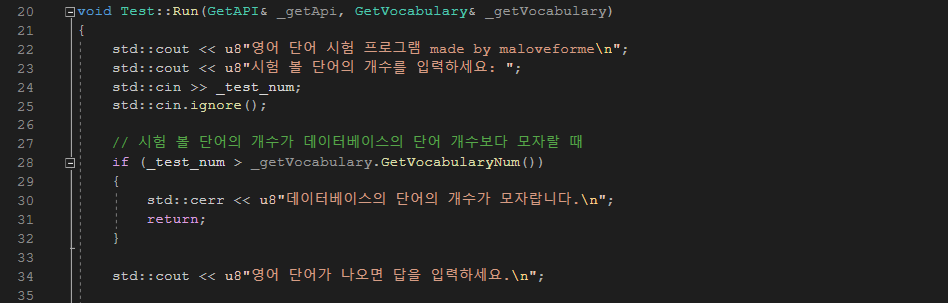
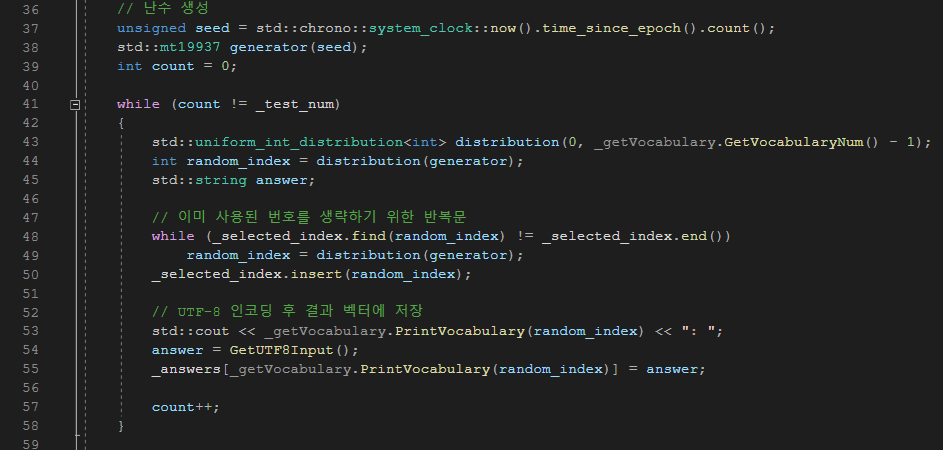
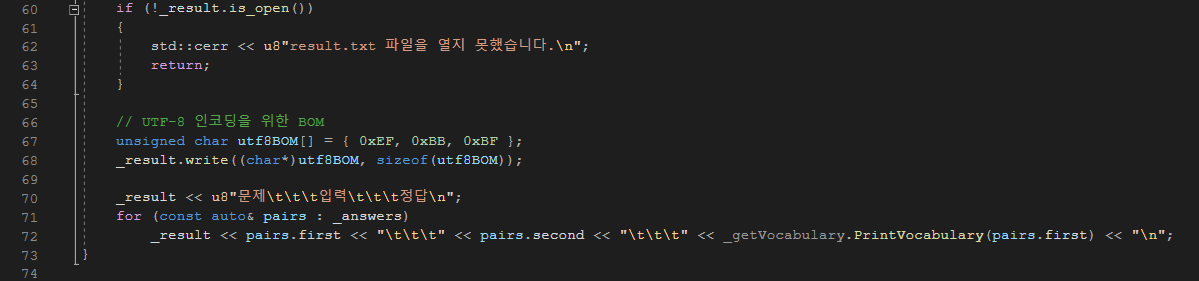
시험지를 출력하는 함수다. 먼저 출력이 UTF-8 형식으로 이루어져 있으므로, 데이터의 일관성을 위해 문자열에 u8 접두사를 붙여 UTF-8 형식으로 출력하게 설정하였다. 시험 볼 단어의 개수를 입력받아, 맵에 저장되어 있는 개수보다 작거나 같을 때만 실행하게 조건을 걸어 두었다.
그리고 난수 생성을 위해 random 라이브러리에 있는 mt19937 알고리즘을 채택하였으며, 중복된 문제 출제를 방지하기 위해 set 컨테이너를 활용하였다. 그리고 사용자의 답변을 UTF-8로 인코딩 후 결과 벡터에 저장하였으며, 해당 내용을 result.txt 파일에 써서 출력하게 하였다.
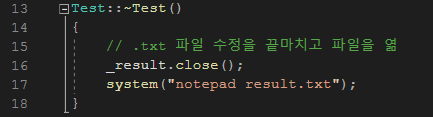
그리고 Test 클래스가 소멸할 때 결과 파일인 result.txt 파일을 열게 하였다.
개선사항
지난 ver 1.0 포스팅 때 언급한 개선사항 4개 중 2개(코드의 구조화, 객체 지향 설계)를 완료하였다. 현재 개강을 한 대학생이기 때문에 업데이트가 느릴 수 있지만, 빠른 시간 내에 결과 출력을 깔끔하게 정렬하는 것을 목표로 하겠다.
'Program > Dictionary' 카테고리의 다른 글
| [Dictionary] 영어 단어 시험지 ver 1.1 (사용법) with Notion (0) | 2023.09.05 |
|---|---|
| [Dictionary] 영어 단어 시험지 ver 1.0 with Notion (0) | 2023.08.29 |