<본 카테고리는 "혼자 공부하는 컴퓨터구조 + 운영체제" 책과 강의를 기반으로 작성하였습니다>
문자 표현
개요
문자를 0과 1의 의진 코드로 변환하는 메커니즘을 공부하기에 앞서, 문자 표현과 관련된 기본적인 용어들을 간단하게 살펴보자. 먼저 문자 집합(character set)이라는 개념이 존재한다. 이는 컴퓨터가 인식하고 표현할 수 있는 문자의 집합체를 의미한다. 컴퓨터는 이러한 문자 집합에 포함된 문자들만 인식 가능하다.
하지만 문자 집합에 속한 문자라 하더라도 컴퓨터가 바로 이해하는 것은 아니다. 사람이 이해하는 문자를 컴퓨터가 이해할 수 있는 이진 코드, 즉 0과 1로 변환해야만 컴퓨터가 인식하고 처리할 수 있다. 이처럼 인간이 이해하는 정보를 컴퓨터가 처리할 수 있는 형태로 변환하는 과정을 인코딩(encoding)이라고 한다. 반대로 컴퓨터가 처리하는 정보를 인간이 이해할 수 있는 형태로 해석하는 과정을 디코딩(decoding)이라고 한다.
ASCII Code
지금부터 다양한 문자 집합과 인코딩 방법들에 대해 알아볼 것이다. 가장 먼저 다룰 문자 집합은 아스키(ASCII: American Standard Code for Information Interchange) 코드다. 이는 초창기 문자 집합 중 하나로, 영어 알파벳과 아라비아 숫자, 그리고 일부 특수 문자를 포함한다. 아스키 코드의 각 문자들은 총 8비트로 구성되어 있다. 이 중 7비트는 문자를 나타내기 위해 사용되고, 1비트는 오류를 검출하는 패리티 비트(parity bit)로 사용된다. 다음은 아스키 코드 표다.
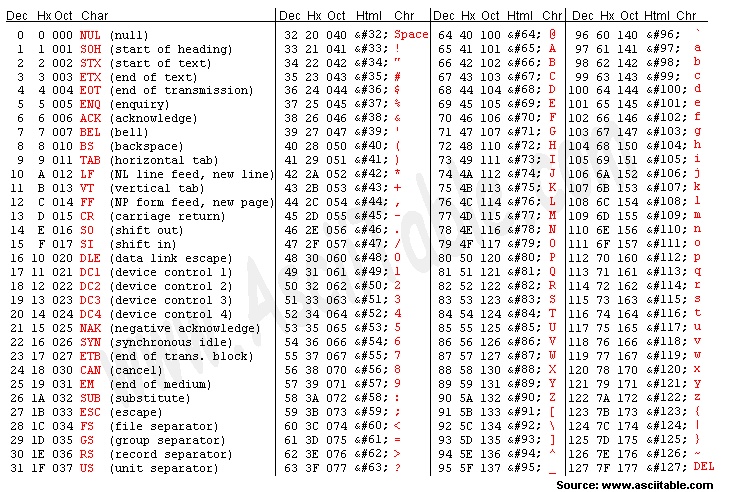
예를 들어 'A'는 10진수 65로 인코딩 되고, 'a'는 10진수 97로 인코딩 된다. 이때 각 글자에 부여된 고유한 값을 코드 포인트(code point)라고 한다. 여기서 A의 코드 포인트는 65고, a의 코드 포인트는 97이 된다.
이를 가장 직관적으로 확인할 수 있는 것은 다음 코드를 작성하고 실행시키는 것이다.
#include <iostream>
int main()
{
std::cout << (char)65 << "\n";
std::cout << 'A' << "\n";
}
이렇듯 아스키 코드는 매우 간단하게 인코딩 된다는 장점이 있지만, 한글 같은 문자를 표현할 수 없고, 128개보다 많은 문자를 표현하지 못한다는 단점이 있다. 이를 해결하기 위해 아스키코드에 1비트를 추가한 확장 아스키가 등장하기도 했지만, 그럼에도 표현 가능한 문자의 수는 256개여서 턱없이 부족했다.
EUC-KR
한글 인코딩을 이해하려면 한글의 특수성부터 이해해야 한다. 알파벳을 쭉 이어 쓰면 단어가 되는 영어와는 달리, 한글은 각 음절 하나하나가 초성, 중성, 종성의 조합으로 이루어져 있다. 따라서 한글 인코딩에는 완성된 하나의 글자에 고유한 코드를 부여하는 완성형 인코딩 방식과, 각각의 비트열을 할당하여 그것들의 조합으로 하나의 글자 코드를 완성하는 조합형 인코딩 방식이 있다.

이러한 EUC-KR은 KS X 1001, KS X 1003이라는 문자 집합을 기반으로 하는 대표적인 완성형 인코딩 방식이다. 즉, EUC-KR 방식은 한글 단어에 2바이트 크기의 코드를 부여한다. 이러한 방식으로 총 2350개 한글 단어를 표현할 수 있지만, 이는 모든 한글 조합을 표현할 수 있을 정도로 많은 양은 아니다.
유니코드
앞선 EUC-KR 인코딩 방식을 채용하면 한국어를 코드를 표현할 수 있다. 하지만 언어별로 인코딩을 나라마다 해야 한다면 다국어를 지원하는 프로그램을 만들 때 각 나라 언어의 인코딩을 모두 알아야 하는 번거로움이 있다. 다시 말해, 모든 언어를 아우르는 문자 집합과 통일된 표준 인코딩 방식이 있다면 언어별로 인코딩하는 수고로움을 덜 수 있다. 이러한 접근에서 나온 것이 유니코드(Unicode) 문자 집합이다.
현대 문자를 표현할 때 가장 많이 사용되는 표준 문자 집합인 유니코드 문자 집합은 EUC-KR보다 훨씬 많은 한글을 포함하며, 대부분 나라의 문자, 특수문자, 화살표, 이모티콘 등을 코드로 표현할 수 있게 구현해 놓았다. 다음은 유니코드 문자 집합의 예시다.

이런 유니코드 인코딩 방식에는 크게 UTF-8, UTF-16, UTF-32 등이 있다. 여기서 UTF란 Unicode Transformation Format의 약어로 유니코드를 인코딩하는 방법을 의미한다. 가장 대표적인 UTF-8을 예로 들어보겠다. UTF-8은 통상 1바이트부터 4바이트까지 가변 길이 인코딩 결과를 만들어 낸다. 이는 유니코드 문자에 부여된 값의 범위에 따라 인코딩한 결과가 몇 바이트가 될지 결정한다. 예를 들면, 유니코드 문자에 부여된 값의 범위가 0부터 007F(16)까지는 1바이트로 표현하고, 0080(16)부터 07FF(16)까지는 2바이트로 표현한다.

이제 '한'이라는 글자를 UTF-8 방식으로 인코딩하는 방법을 살펴보자. '한'에 부여된 값은 D55C(16)이다. 이 값은 다음 표에 따라 3바이트로 결정된다.

D55C(16) = 1101 0101 0101 1100(2)이므로, 1바이트에는 1100 + 1100 1101, 2바이트에는 10 + 010101, 3바이트에는 10 + 10011100이 들어간다. 따라서 11001101 10100101 10011100(2)이 '한'이 UTF-8 방식으로 인코딩 된 값이다.
요약
문자 집합
1. 정의: 컴퓨터가 인식하고 표현할 수 있는 문자의 집합체
2. 종류
a. 아스키 코드: 초창기 문자 집합 중 하나로서, 오류 검출 코드인 패리티 비트와 7개의 비트로 이루어져 있음
b. EUC-KR: 한글 환성형 인코딩 방식. ( ↔ 조합형 인코딩 방식)
c. 유니코드: 현대 문자를 표현할 때 가장 많이 사용되는 표준 문자 집합. UTF-8, UTF-16, UTF-32 등이 존재
'CS > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터구조] CPU의 작동 원리 (2) (0) | 2023.06.11 |
|---|---|
| [컴퓨터구조] CPU의 작동 원리 (1) (0) | 2023.06.09 |
| [컴퓨터구조] 명령어의 이해 (0) | 2023.06.03 |
| [컴퓨터구조] 데이터의 이해(1) (0) | 2023.06.01 |
| [컴퓨터구조] 개요 (0) | 2023.05.26 |